Aadityan Ganesh, Haran Mouli and Hari Ramasubramanian
In 2 lines: Not surprisingly, we argue that ranking players according to points at the end of a double round-robin tournament increases the likelihood of ordering the players in decreasing order of strengths. However, this leads to a surprising corollary, conditioned on two players ending up with the same number of points, no tie-break that relies purely on the tournament results identifies the stronger among the two players with probability better than half.
Designing effective tie-breaking protocols is a critical challenge in competitive settings. Formally, a tie-breaking protocol can be viewed as a mapping from all available information in a tournament to an ordered ranking of participants. The simplest and most widely used method is ranking by total points, but tie-breaks can become much more intricate. In this article, we consider designing tie-breaking protocols aimed at enhancing the likelihood of the stronger player finishing higher in the rankings.
Tie-breaks often rely on external metrics that go beyond the match results themselves. For example, cricket and football use measures like net run rate or goal difference to capture the margins of victories and defeats—details not apparent from results alone. We say such tie-breaks are exogenous. On the other hand, many sports, like chess, use tie-breakers derived entirely from match outcomes, which we call endogenous tie-breaks. Ranking players by points is a straightforward example of an endogenous tie-break. Chess also employs more nuanced methods, such as the Sonneborn-Berger score (which factors in the points of defeated and drawn opponents) or counting the number of wins, particularly those achieved with Black pieces.
Interestingly, chess relies on endogenous tie-breakers even in double-round robin tournaments, where players play each other once with both white and black pieces. Famously, in the 2013 Candidates Tournament (the tournament to decide the challenger for the World Champion crown), Carlsen and Kramnik finished with equal points, but Carlsen was declared the winner due to more wins. One might argue that the result to be fair and Carlsen’s higher number of wins to be a sign of dominance. On the other hand, one can also argue that Kramnik’s fewer losses reflect his consistency. Such disagreements are inherent to any endogenous tie-breaking system. For example, breaking ties based on a better head-to-head score in the tournament can be seen as favouring the player who had a poorer tournament against all other opponents. We formalize this intuition to argue that all endogenous tie-breaking rules are effectively equivalent to a coin toss: the probability of the stronger player ranking higher, given equal points, is always one-half, regardless of the tie-breaker used.
Theorem 1: In a double round-robin tournament for a symmetric game where two players finish with the same number of points, the probability of any endogenous tie-break ranking the stronger player above the weaker player is exactly half.
The Davidson Model
We adopt the Davidson model to assign probabilities for various outcomes in a tournament. Intuitively, it is not guaranteed that a stronger player will always beat a weaker player. A player is considered strong when they have a large probability of winning. The Davidson model captures this intuition.
The Davidson model assumes the existence of an inherent strength s for each player in the tournament. For a symmetric game with three possible results — win, loss and draw, and two players with strengths 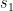
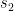
- player 1 wins with probability
,
- the game ends in a draw with probability
, and,
- player 2 wins with probability
,
for some constant 

For example, the Elo rating system used in chess, go and football is a variant of the Davidson model. The rating 


The Davidson model can be extended to games with a bias between the players. Traditionally, the player with the white pieces has held a slight advantage over the player with the black pieces in the highest levels of chess. Such bias can be accommodated by multiplying the first player’s strength 

Preparing the Final Standings
While we will not be able to learn the exact strengths of the players at the end of the tournament, we can still hope to find a ranking algorithm that increases the likelihood of ranking the players in decreasing order of strengths. Formally, a tournament 








By Bayes rule, we have 


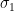
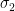

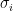
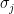



Not surprisingly, ranking players by points (assuming 1 point for a win, 1/2 for a draw and none for a loss) maximizes the above probability in a round-robin tournament. In the theorem below, we will argue that the optimal ranking algorithm should always rank a player

Theorem 2: For a player 
Proof: We will pretend we know the strengths 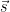




Let 

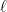
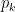

From the above equation, it is clear that 








Theorem 1 that claims tie-breaking is pointless when two players are tied on the same number of points follows immediately follows immediately from the proof of Theorem 2. When 



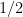
However, tie-breakers can be extremely useful despite what Theorem 1 suggests. For that matter, Theorem 1 observes that conditioned on two players being tied on points, no tie-break can perform strictly worse than another. Thus, beyond the goal of ranking players according to their strengths, the tie-break can be used to elicit an intended behaviour from the players. For example, tournament organizers might want to reward players for playing more entertaining chess and as a result, can consider breaking ties in favour of the player with a higher number of wins.
