In two lines: Estimating the expected value of a distribution through sampling is fundamental to econometrics and has broad applications. Although the empirically estimated mean is an unbiased estimator of the expected value (corresponding to a high accuracy), understanding its precision is crucial. This post explores techniques to show high precision, including:
- Tractable estimates of the mean through Chernoff bounds
- Tighter confidence intervals through the DKW inequality for light-tailed distributions
- Fancier (potentially tighter) concentration bounds by modifying the DKW
____________________________________________________________________________________________
Consider estimating the expected value of a distribution empirically through finite sampling — we want to give a confidence interval ![[\underline \mu, \overline \mu]](https://s0.wp.com/latex.php?latex=%5B%5Cunderline+%5Cmu%2C+%5Coverline+%5Cmu%5D&bg=ffffff&fg=000&s=0&c=20201002) such that the mean
such that the mean  of the distribution lies inside this interval with high probability. Given
of the distribution lies inside this interval with high probability. Given  samples
samples  drawn i.i.d from a distribution
drawn i.i.d from a distribution  , the average
, the average  of the samples is an unbiased estimator of the expected value of , i.e,
of the samples is an unbiased estimator of the expected value of , i.e, ![\mathbb{E}_{s \sim F}[s] = \mathbb{E}_{s_1, \dots, s_n \sim F}[\frac{s_1 + \dots + s_n}{n}]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7Bs+%5Csim+F%7D%5Bs%5D+%3D+%5Cmathbb%7BE%7D_%7Bs_1%2C+%5Cdots%2C+s_n+%5Csim+F%7D%5B%5Cfrac%7Bs_1+%2B+%5Cdots+%2B+s_n%7D%7Bn%7D%5D&bg=ffffff&fg=000&s=0&c=20201002) .
.
For a distribution supported on ![[a, b]](https://s0.wp.com/latex.php?latex=%5Ba%2C+b%5D&bg=ffffff&fg=000&s=0&c=20201002) , the above empirical estimate concentrates quite well around the expected value too. In other words, a standard Chernoff bound suggests
, the above empirical estimate concentrates quite well around the expected value too. In other words, a standard Chernoff bound suggests

However, the above concentration guarantee is heavily dependent on the extremes of the support of the distribution . For instance, if we knew that the probability of a sample being drawn outside ![[\frac{a+b}{2} - \delta, \frac{a+b}{2} + \delta]](https://s0.wp.com/latex.php?latex=%5B%5Cfrac%7Ba%2Bb%7D%7B2%7D+-+%5Cdelta%2C+%5Cfrac%7Ba%2Bb%7D%7B2%7D+%2B+%5Cdelta%5D&bg=ffffff&fg=000&s=0&c=20201002) is an extremely small constant
is an extremely small constant  , Bernstein’s inequality gives a much stronger bound. The variance
, Bernstein’s inequality gives a much stronger bound. The variance 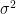 of the distribution can be bounded above by
of the distribution can be bounded above by  . Bernstein inequality yields
. Bernstein inequality yields

However, there might be applications where we suspect that the distribution is heavily concentrated around the mean, but with no provable guarantees on the variance . Bernstein’s inequality can no longer be applied, but we would like to bootstrap the concentration bound with our beliefs to potentially get stronger bounds than Chernoff’s inequality.
Attempt 1: The DKW Inequality
Along with the expected value, it turns out, the entire cumulative distribution function (CDF) concentrates quite well when sufficiently many samples are constructed. For a bunch of samples  , let
, let  be the empirical distribution with CDF
be the empirical distribution with CDF  . Then, by the DKW inequality,
. Then, by the DKW inequality,

In other words, except for a very small probability, the CDF and the empirical CDF  differ only by a small constant
differ only by a small constant  on all points
on all points  on the support of . We will use the concentration of the entire distribution to get a tighter concentration guarantee around the estimated mean.
on the support of . We will use the concentration of the entire distribution to get a tighter concentration guarantee around the estimated mean.
Consider inflating the empirical distribution by throwing away the smallest  samples
samples  and replacing them by the supremum
and replacing them by the supremum  of the distribution . The inflated distribution
of the distribution . The inflated distribution  has a support
has a support ![[s_{n(1-\epsilon)}, b]](https://s0.wp.com/latex.php?latex=%5Bs_%7Bn%281-%5Cepsilon%29%7D%2C+b%5D&bg=ffffff&fg=000&s=0&c=20201002) and a CDF
and a CDF  for all in the support of (we hav essentially moved an mass below
for all in the support of (we hav essentially moved an mass below  all the way to ). Coupling with the DKW inequality, except for a small probability,
all the way to ). Coupling with the DKW inequality, except for a small probability,  and thus, has a higher expected value than
and thus, has a higher expected value than  .
.
Similarly, one can construct a deflated distribution  by dropping the largest
by dropping the largest  samples from and replacing them with the infimum
samples from and replacing them with the infimum  of the distribution . By a symmetric version of the DKW inequality, we can conclude that the expected value of the distribution is smaller than that of with high probability.
of the distribution . By a symmetric version of the DKW inequality, we can conclude that the expected value of the distribution is smaller than that of with high probability.
Theorem 1: Except for a probability  ,
, ![\mathbb{E}_{s \sim \underline F}[s] \leq \mathbb{E}_{s \sim F}[s] \leq \mathbb{E}_{s \sim \overline F}[s]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7Bs+%5Csim+%5Cunderline+F%7D%5Bs%5D+%5Cleq+%5Cmathbb%7BE%7D_%7Bs+%5Csim+F%7D%5Bs%5D+%5Cleq+%5Cmathbb%7BE%7D_%7Bs+%5Csim+%5Coverline+F%7D%5Bs%5D&bg=ffffff&fg=000&s=0&c=20201002) where and are constructed by deflating and inflating an empirical distribution constructed from with samples.
where and are constructed by deflating and inflating an empirical distribution constructed from with samples.
Theorem 1 gives a tighter confidence interval than the one obtained from the Chernoff bound. Setting  in the Chernoff bound, we get
in the Chernoff bound, we get
![Pr(\mathbb{E}_{s \sim \hat F}[s] - (b-a) \, \delta \leq \mu \leq \mathbb{E}_{s \sim \hat F}[s] + (b-a) \, \delta) > 1 - 2e^{-2n \delta^2},](https://s0.wp.com/latex.php?latex=Pr%28%5Cmathbb%7BE%7D_%7Bs+%5Csim+%5Chat+F%7D%5Bs%5D+-+%28b-a%29+%5C%2C+%5Cdelta+%5Cleq+%5Cmu+%5Cleq+%5Cmathbb%7BE%7D_%7Bs+%5Csim+%5Chat+F%7D%5Bs%5D+%2B+%28b-a%29+%5C%2C+%5Cdelta%29+%3E+1+-+2e%5E%7B-2n+%5Cdelta%5E2%7D%2C&bg=ffffff&fg=000&s=0&c=20201002)
where is the expected value of the distribution . For the same probability, Theorem 1 guarantees that . We will observe that ![\mathbb{E}_{s \sim \overline F}[s] \leq \mathbb{E}_{s \sim \hat F}[s] + (b-a) \, \delta](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7Bs+%5Csim+%5Coverline+F%7D%5Bs%5D+%5Cleq+%5Cmathbb%7BE%7D_%7Bs+%5Csim+%5Chat+F%7D%5Bs%5D+%2B+%28b-a%29+%5C%2C+%5Cdelta&bg=ffffff&fg=000&s=0&c=20201002) . Remember that was constructed from in two steps:
. Remember that was constructed from in two steps:
- Add
 copies of the supremum . This would increase the expected value by
copies of the supremum . This would increase the expected value by  .
.
- Delete the smallest samples. Note that all samples are larger than the infimum , and we decrease the expected value when removing the smallest few samples by
 .
.
Combining the above two bullets proves the observation. From a similar argument, we can also conclude that ![\mathbb{E}_{s \sim \hat F}[s] - (b-a) \, \delta \leq \mathbb{E}_{s \sim \underline F}[s]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7Bs+%5Csim+%5Chat+F%7D%5Bs%5D+-+%28b-a%29+%5C%2C+%5Cdelta+%5Cleq+%5Cmathbb%7BE%7D_%7Bs+%5Csim+%5Cunderline+F%7D%5Bs%5D&bg=ffffff&fg=000&s=0&c=20201002) . If the smallest few samples that are thrown away in bullet 2 are much larger than the infimum (which is the case when we suspect that the tail of the distribution is extremely light, and not a lot of probability mass is around ), then Theorem 1 starts performing much better than the Chernoff bound, achieving the goal that we set out to reach.
. If the smallest few samples that are thrown away in bullet 2 are much larger than the infimum (which is the case when we suspect that the tail of the distribution is extremely light, and not a lot of probability mass is around ), then Theorem 1 starts performing much better than the Chernoff bound, achieving the goal that we set out to reach.
However, we are trading performance for simplicity. The confidence interval given by the Chernoff bound is extremely elegant– compute the empirical average and look at the interval with diameter on either side– and is much more useful if the concentration bound is to be fit inside a larger theoretical proof looking for closed form expressions. Theorem 1, on the other hand, is useful if estimating the confidence interval is the ultimate goal.
Attempt 2: Bootstrapping the DKW
The above approach already presents non-trivial improvements from the guarantees given by the Chernoff bound. However, the inflation and deflation procedures are themselves quite wasteful and can be improved further.
Consider the inflation procedure. We throw away the smallest few samples and replace them with the supremum of the distribution . What if we had a better idea of the distribution of the “larger values” (the stronger percentiles) of the distribution ? Instead of replacing all the thrown away samples by , we can replace at least some of them with samples from the distribution of the larger values. Fortunately for us, we have drawn samples from , and some of these are going to have a strong percentile! We will be duplicating our extra-large samples to replace the smallest few samples that we will be throwing away.
Let  . Consider the largest few samples
. Consider the largest few samples  for some
for some  . Insert
. Insert  copies of each of these
copies of each of these  samples, so that a total of large samples are injected in all to replace the small samples that have been thrown away. Note that we are risking that all the largest samples that we ended up drawing do not really belong to the stronger percentiles of . However, it can be proved that such an event occurs with an extremely small probability. The magnitude of this probability can be made smaller than the probability of the empirical distribution and the distribution of the population not being within from each other (
samples, so that a total of large samples are injected in all to replace the small samples that have been thrown away. Note that we are risking that all the largest samples that we ended up drawing do not really belong to the stronger percentiles of . However, it can be proved that such an event occurs with an extremely small probability. The magnitude of this probability can be made smaller than the probability of the empirical distribution and the distribution of the population not being within from each other (  given by DKW). We will call the above variant of inflating the empirical distribution as stratified inflation. We can define an analogous stratified deflation procedure too. We summarize the above discussion in the theorem below. The readers can find the formal proof of Theorem 2 in Appendix F.3 in the paper cited below.
given by DKW). We will call the above variant of inflating the empirical distribution as stratified inflation. We can define an analogous stratified deflation procedure too. We summarize the above discussion in the theorem below. The readers can find the formal proof of Theorem 2 in Appendix F.3 in the paper cited below.
Theorem 2 (Ferreira et al., 2024): Except for a probability  , the empirical distributions and achieved through stratified inflation and deflation respectively satisfy .
, the empirical distributions and achieved through stratified inflation and deflation respectively satisfy .
The stratified inflation and deflation procedure satisfy a much stronger property than described in Theorem 2. Similar to inflate, the probability that a sample  drawn from the distribution constructed through stratified inflation is larger than some value is greater than
drawn from the distribution constructed through stratified inflation is larger than some value is greater than  , the probability that drawn from is larger than . Stratified inflation and stratified deflation has even lesser dependence on the supremum and infimum of and gives a tighter confidence interval than the ones given by (vanilla) inflation and deflation for distributions with extremely light tails. Except for the additional
, the probability that drawn from is larger than . Stratified inflation and stratified deflation has even lesser dependence on the supremum and infimum of and gives a tighter confidence interval than the ones given by (vanilla) inflation and deflation for distributions with extremely light tails. Except for the additional  probability of failure, stratified inflate and stratified deflate gives better empirical bounds on the expected value than both (vanilla) inflate and deflate and the tractable bounds given by Chernoff’s bounds.
probability of failure, stratified inflate and stratified deflate gives better empirical bounds on the expected value than both (vanilla) inflate and deflate and the tractable bounds given by Chernoff’s bounds.
References
Matheus V. X. Ferreira, Aadityan Ganesh, Jack Hourigan, Hannah Huh, S. Matthew Weinberg, and Catherine Yu. 2024. Computing Optimal Manipulations in Cryptographic Self-Selection Proof-of-Stake Protocols. In The 25th ACM Conference on Economics and Computation (EC ’24), July 8–11, 2024, New Haven, CT, USA. ACM, New York, NY, USA, 43 pages. https://doi.org/10.1145/3670865.3673602
